Projects
-

LIquid Distributed In-memory Graph Database
LIquid is an essential component holding billions of data on LinkedIn’s economic graph. This in-memory, low-latency distributed database delivers value to the members by helping them quickly find what they're interested in, like connecting with a coach, getting advice on skills, or finding specialized talent for an important project.
I led the efforts to build a client framework that makes it easier to ingest new data into the platform and accelerate the onboarding of new clients to explore and interact with our infrastructure.
With these efforts, we were able to migrate a legacy system for People You May Know and accelerate the introduction of new features on this module which resulted in overall business wins.
-

Graph Modeler - Graph Studio in ADB
The Graph Modeler in ADB provides capabilities to define a graph out of relational data by defining a customizable graph model, managing existing models/graphs, and interacting with a Notebooks feature to provide efficient querying, visualization, and analytics to property graph data stored in the Oracle Autonomous Database (ADB).
I paired with a Sr. PM to design the wireframes and interactions of the Graph Modeler and led a team of five engineers to implement the Front-end and Back-end features to create the mappings from relational tables to graph data.
-
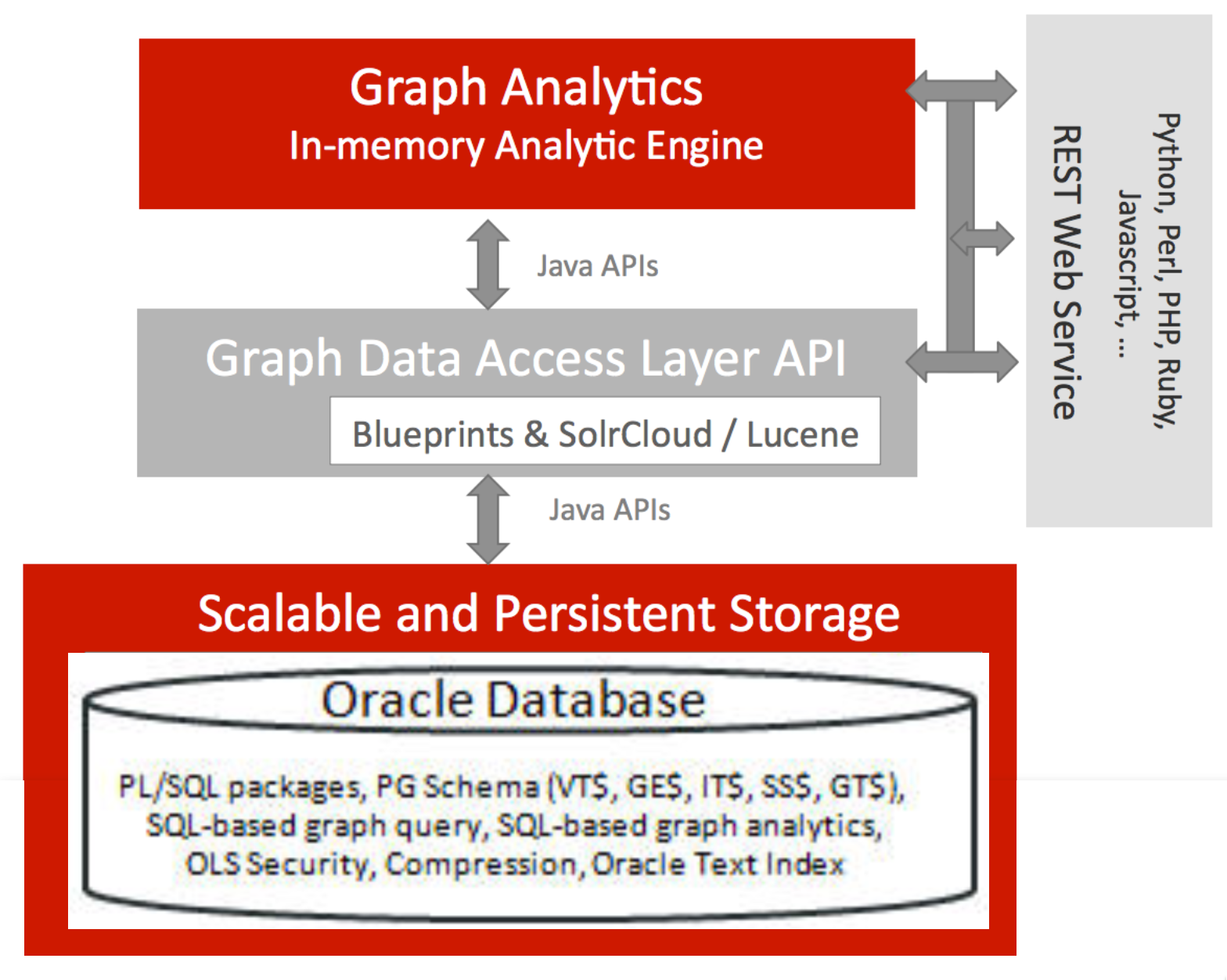
Property Graph Support on Oracle Spatial and Graph - Oracle Database 12c to 20.4
The Property Graph feature delivers advanced graph query and analytics capabilities in Oracle Database. This feature supports graph operations, indexing, queries, search, and in-memory analytics.
I worked along with a team of 3 engineers to build the Data Access Layer to efficiently store graph data as relational tables and enable operations to query, run analytics, and visualizations over the graph data. With our tools, we were able to build proof of concepts for a US bank and international banks to address fraud detection.
-

Property Graph Support on Oracle Big Data Spatial and Graph
The Property Graph Support in Oracle Big Data Spatial and Graph provided optimized data storage, querying, and analysis of property graphs. Property Graphs are commonly used to represent data for social networks, customer recommendations, and knowledge graphs.
I worked as a Tech Lead implementing the data access layer to manage graph data into Apache HBase and also led two other engineers working on implementing such features on top of Oracle NoSQL Database.
Different from relational databases, this feature provided distributed, scalable, and secure graph management.
With our tools, we were able to build a proof of concept and onboard two Latin-American and Spanish banks to use our feature for fraud detection and customer 360, which resulted in business wins for the company.
-
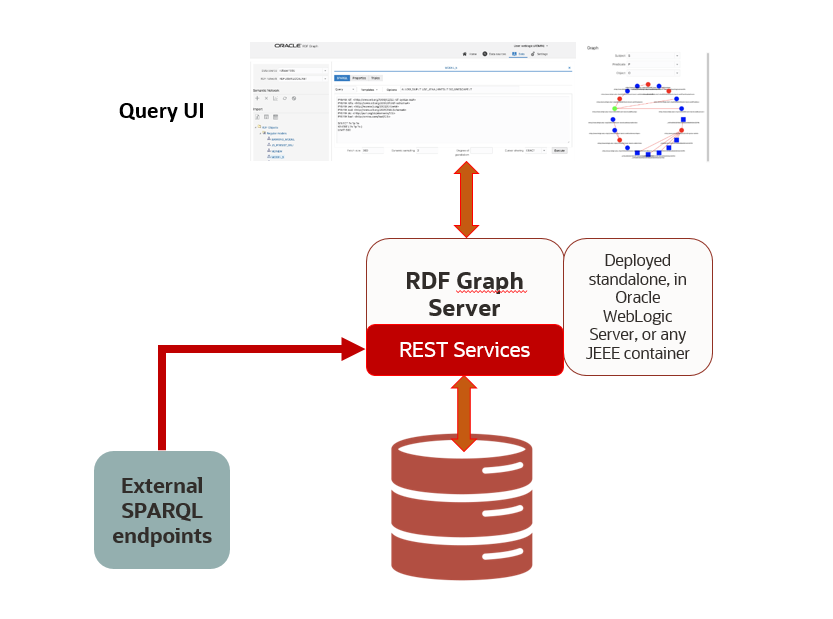
RDF Graph Support for Oracle Graph Database
RDF Graph Support for Oracle Database enables you to create one or more semantic networks in an Oracle database. Each network contains semantic data (also referred to as RDF data).
I worked as a Tech Lead for this project focusing on the maintainability of the existing features supported since Oracle 10c, guiding two junior engineers in the implementation of new features and portability of querying features to use a SPARQL to SQL compiler developed by other members of the team.
-

RDF Graph Support for Oracle NoSQL Database
RDF Knowledge Graph provides capabilities to manage and query semantic data in a high scalable and fault-tolerant environment. We designed a model to represent triples as keys in any K/V store as well as a Query engine that provides support for complex SPARQL queries.
Additionally, the RDF Knowledge Graph provides support for the Joseki Web service endpoint to execute SPARQL queries using an HTTP service.
I paired with an Architect to design the schema that we will use to load the RDF data into a NoSQL Key/Value store. I also worked as the sole developer working on the development, testing, and documentation of the RDF Graph feature for the Oracle NoSQL Database.
-

AURA: AUtonomic Requirement-based dAtaspaces
This thesis project focused on building an autonomic resources management system based on the semantics of the resources. Our key goal is to characterize data sources (images, documents, databases) with metadata describing the semantics of their content, and using a set of mapping rules to identify resources that can be related to a user’s request.
Based on the user request, the management system identifies potential resources that can help solve a problem, or identify existing sub-spaces to combine them all together to provide a unique view for each user. These sub-spaces adapt automatically based on the new acquisition of resources, their removal, or data updates.
This project applies Answer Sets programming, and autonomic computing concepts and was implemented using DLV-K logic-based planning System.
-

BioVLab: Biology Virtual Laboratory
This Biology Virtual laboratory manages bioinformatic resources based on their semantics. When a researcher is interested in studying a biological problem, he must specify a set of concepts defining the semantics of the problem. With these data, the system generates a view that integrates resources defined by the concepts of the query in a partial or total way. Once the view is created, it is returned to the user, as well as those resources that make reference to such concepts. These views are stored by the system in order to maintain a problem catalog.
Our prototype implements a set of schemas representing the content of different sources. We built a first validation test by defining the knowledge domain of the system through the existing bio-ontologies: Cell ontology, Amino-Acid ontology, Fungi anatomy ontology, and Clinical ontology for breast cancer.
BioVLab was implemented in the JAVA platform 1.5.0. Metadata ontologies were built using the Protégé ontology editor that allows designing ontologies in OWL-DL language. Query processing and knowledge inferences are achieved using a Racer inference engine, which uses a set of mechanisms for querying, creating, and managing knowledge bases. Our ontologies are visualized using the JUNG framework.